EFDC+ MPI Multi-core Scaling Study
In 2020, DSI implemented MPI in EFDC+ to improve model run time. We created a detailed model of the Chesapeake Bay with one million computational cells to test this new functionality and demonstrated the outstanding improvement in performance. Since then, there have been an increasing number of users requesting information on how to take advantage of this capability. Cost-effective high-performance computing (HPC) is increasingly available, providing access to multiple cores and allowing significant time savings when running large models. This blog describes our latest testing and recommendations on machine configuration to obtain the best results with EFDC+.
EEMS was designed predominantly for the Windows operating systems (OS). This is because the pre- & post-processor, EFDC+ Explorer, requires the GUI available in Windows. However, HPC typically uses Linux operating systems, making it necessary to ensure EFDC+ performs as well on Linux as it does on Windows. Furthermore, EFDC+ is now fully open-source, and users are compiling EFDC+ for their own platforms and versions of Linux.
One of the primary motivations for this testing was to better understand how EFDC+ performs with scaling. To conduct this testing, we used a DSI 48-core machine and a cloud computing platform utilizing AWS. The findings in this blog should help users of EFDC+ better configure their model runs.
System Summary
We used two system configurations, DSI Milan-01 and AWS c6a, and compiled EFDC+ v11.1.0 with the Intel ifort v2021.4.0 compiler using the following options:
-traceback -qopenmp -O3 -real-size 64 -fpe0 -fp-model=source -fp-speculation=safe
The detailed specifications of the two systems are provided in Table 1 below.
Table 1. DSI Milan-01 vs AWS c6a.48xlarge configuration
| Operating System: | Ubuntu 20.04.3 LTS | Ubuntu 20.04.3 LTS |
| Model: | Dell Inc. PowerEdge R7525 | Amazon EC2 c6a.48xlarge |
| CPU Information | ||
| Name | AMD EPYC 7443 | AMD EPYC 7R13 |
| Topology | 2 Processors, 48 Cores | 2 Processors, 96 Cores |
| Base Frequency | 2.84 GHz | 2.65 GHz |
| L1 Instruction Cache | 32.0 KB x 24 | 32.0 KB x 24 |
| L1 Data Cache | 32.0 KB x 24 | 32.0 KB x 24 |
| L2 Cache | 512 KB x 24 | 512 KB x 24 |
| L3 Cache | 16.0 MB x 4 | 32.0 MB x 3 |
| NUMA Configuration | NPS=1 | Unknown |
| Memory Information | ||
| Capacity: | 252 GB | 370 GB |
| Error Correction: | Multi-bit ECC | Multi-bit ECC |
| Speed: | 3200 MT/s | Unknown |
Benchmark Results
The first round of benchmarking was completed using our own Milan-01 machine, after which the same benchmarks were run on the AWS machine as described below.
The Chesapeake Bay Model is described in our previous blog. However, for this set of runs the model was slightly modified to consist of 203,973 horizontal cells and five vertical layers. The model time span was 4 days or 96 hours.
All benchmark runs used the same OMP configuration of 2 cores per domain.
Benchmarks using Milan-01
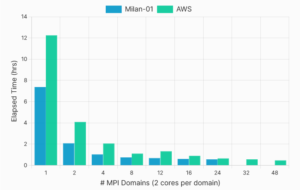
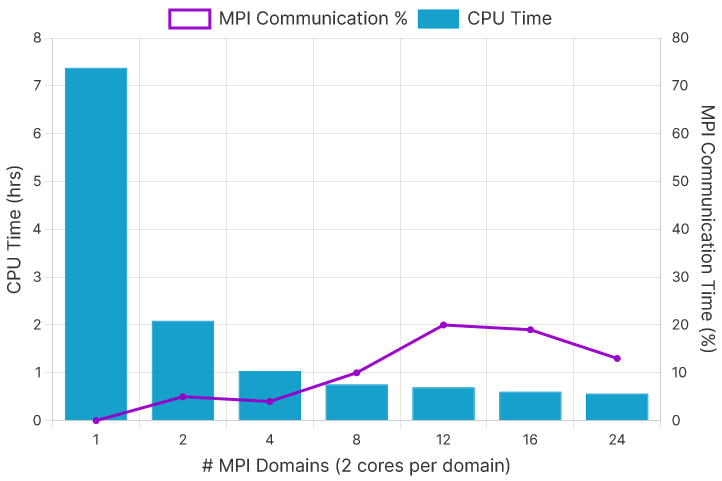
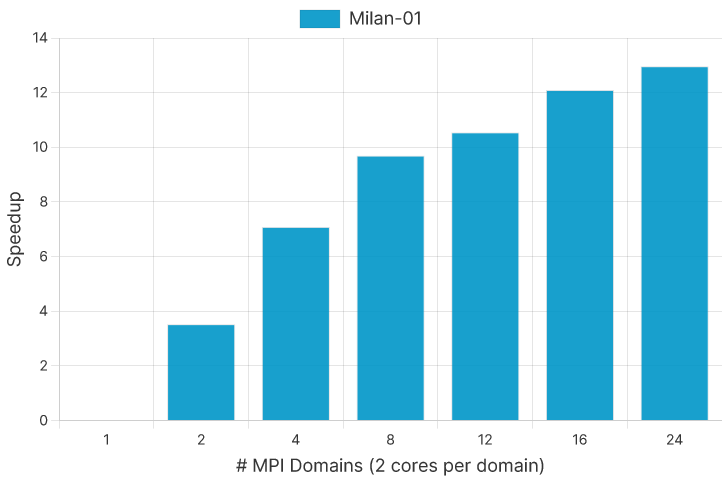
MPI scaling performed exceptionally well on the Milan-01 benchmarks, with total elapsed time dropping from approximately 7 hours and 23 minutes to just 35 minutes (Figure 1). This is equivalent to a speedup of almost 13x from the single-core model when using 24 MPI domains (Figure 2)
Benchmarks using AWS c6a
For the AWS benchmarks, we chose to use their compute-optimized c6a instance. These are powered by the same 3rd generation AMD EPYC architecture as the DSI system and allow for the use of up to 96 physical cores on a single node.
The MPI scaling on AWS for the same model performed well overall, with a total elapsed time of under 30 minutes and a speedup of over 25x at 48 MPI domains (Figures 3 and 4). The exception was the 12-domain (24 cores) run, which increased execution time compared to the eight domain (16 cores) run. It is difficult to determine precisely why this run did not perform in line with the rest. Performance dips at 24 cores were observed in some of our other test runs on AMD Epyc systems. Possible reasons for this may include sub-optimal MPI domain ordering, unbalanced domain decomposition at 12 domains, or excessive NUMA balancing by the host. However, none of these have been confirmed, and these are just initial hypotheses at this point. We plan to investigate these issues in our future testing.
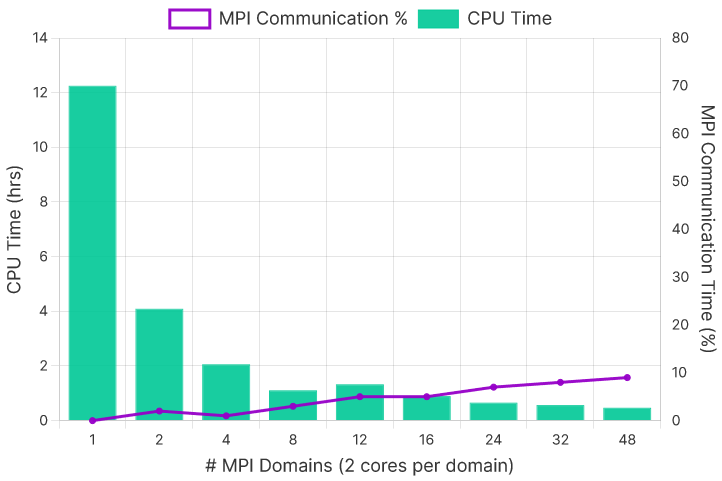
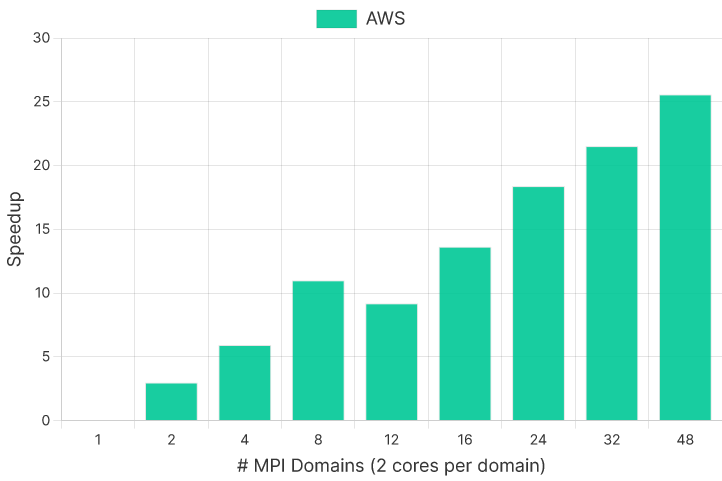
Comparison and Conclusion
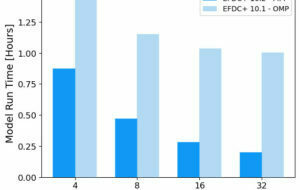
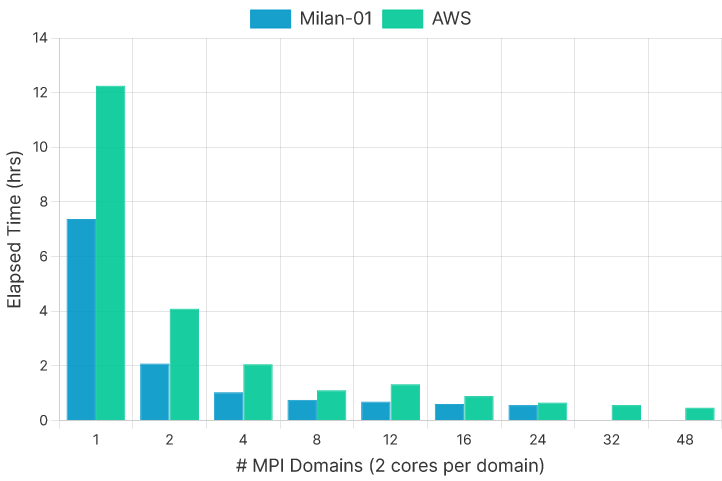
Milan-01 was built with a balance of single-core and multi-core improvement in mind, as not every model will benefit from a high number of subdomains. This balanced configuration is evident in the runtime comparison at lower core counts, where Milan-01 performs significantly better (though it is worth noting that our AWS instance is not running on bare metal). In none of the shared run configurations does the AWS run perform better than the equivalent Milan-01 run (Figure 5). However, we may be able to utilize a greater number of cores relatively easily when using a cloud computing system like AWS.
If we project the AWS results from this 4 day run to a full year simulation, the benefits of being able to scale up to 48 domains are more evident. A single core run would take over 46 days, while a 96 core run would take less than 2 days. The return from higher core counts would likely be even greater if we increased the complexity of the model (i.e. more constituents), which would allow for increased utilization of OMP threads (more on this to come in a future blog).
It has been two years since the original release of the MPI implementation of EFDC+, and we have released multiple new features and updates. It is encouraging to see that speedup resulting from MPI are still performing. We hope that this post will help our user community in evaluating options for future investment in hardware or cloud computing systems.
Please feel free to email us if you have questions or comments.